
The Challenge of Reproducibility
OK, stop me if you think you’ve heard this one before: A colleague has just completed a groundbreaking piece of analysis on a Jupyter notebook that will turn your world upside down. Eager to share the news, she sends you an ‘.ipynb‘ file and a ‘requirements.txt’ for you to reproduce the analysis. So you just create a virtual environment, pip install -r requirements.txt, and you are off to the races!!! Or are you?

I’m sure it’s me, but creating a reproducible environment from a ‘requirements.txt’ for any realistically complex piece of work is a nightmarish experience…
…do not despair though. Enter Docker!!!
![]()
While we unequivocally reject both the morals and the economics of whale exploitation for interoceanic cargo, Docker does have some legitimate use cases. You can containerize your entire environment and share your notebook as a self-contained fully reproducible application by following some relatively simple steps. This is not just a kindness to your colleagues, but also to your future self.
I have been meaning to get in the habit of containerizing my notebooks, but it always felt like a chore. So I decided to write a simple guide as an aide memoire to myself. There are basically seven simple steps to containerize and share a Jupyter notebook: 1) Install Docker Desktop, 2) Create ‘Dockerfile’, 3) Create ‘startup.sh’ 4) Create ‘.dockerignore’ (optional), 5) Build Docker, 6) Run Docker, and 7) Share image. I explain how you can achieve Jupyter reproducibility with Docker below.
Install Docker Desktop
If you haven’t already, download and install Docker Desktop from the official Docker website:
Create ‘Dockerfile’
This file is used to define a Docker image for containerizing your application. Basically just create an empty file called ‘Dockerfile’ in the folder where your notebook is, and add the following lines of code:
- Base Image: I like to specify a base Python image to avoid conflicts with package versions. In this case, I’m using the official Python 3.9.6 slim image from Docker Hub.
- Working Directory: This sets the working directory inside the container to `/app`. This is where the application’s files and code will be located.
- Install Other System Dependencies and Python packages: let us say that we are executing our recent work on video augmentation, so we want to install the ffmpeg and vidaug libraries:
RUN apt-get update && apt-get install -y git
RUN apt-get install -y ffmpeg
RUN pip install git+https://github.com/okankop/vidaug.git
RUN pip install jupyter
- Copy Key Files: Besides the .ipynb, we may want to include some basic files that we need for our analysis and we want to remain static, either to minimize bandwidth use or to ensure persistence. In this case we want to include a zip file with the videos we want to analyse and a startup script to launch the notebook (more later).
COPY movinet_a2_stream /app/movinet_a2_stream
COPY video_augmentation.ipynb /app/video_augmentation.ipynb
COPY videos.zip /app/videos.zip
COPY startup.sh /app/startup.sh
- Make Startup Script Executable: It makes the `startup.sh` script executable within the container.
RUN chmod +x /app/startup.sh
- Expose Ports: It exposes port 8888, which is commonly used for Jupyter Notebook, so that it can be accessed from outside the container.
EXPOSE 8888
- Entry Point: This is the command to run when the container is started. In this case, it runs the `startup.sh` script (see below).
ENTRYPOINT [“/app/startup.sh”]
Create ‘startup.sh’
This a simple shell file to start the notebook, execute it and save it as an html. You may want to let your colleagues know that this will take some time to run.
#!/bin/bash
# Start Jupyter Notebook in the background
jupyter notebook –ip=0.0.0.0 –port=8888 –no-browser –allow-root &
# Wait for the notebook to start (adjust the sleep time as needed)
sleep 5
# Run the Jupyter Notebook and save the output as an HTML file
jupyter nbconvert –execute –to html transfer_learning_with_movinet_seizures_stream.ipynb –output /app/transfer_learning_with_movinet_seizures_stream.html
# Keep the container running
tail -f /dev/null
Create ‘.dockerignore’ (optional)
If you are like me, you will have a bunch of lint in your working folder that you may not want to put into the container. Creating a .dockerignore file is a good idea to optimize Docker image builds by excluding unnecessary files and directories, reducing image size, and improving build performance. Simply create an empty file called ‘.dockerignore’ and add files and folders that you want to exclude.
You may want to exclude entire categories. I have for example a bunch of TensorFlow lite models, logs and gifs that are heavy and not necessary:
*.tflite
*.log
*.gif
You may also want to ignore entire folders:
!bad_videos/
And specific files:
videos_trim.zip
Build Docker
This is both the easiest and hardest part. Easiest because you can build your docker with just one line of code from the terminal:
docker build -t video_augmentation .
Hard because this is the moment of truth, when all the bugs in your code will become apparent. Hopefully there won’t be too many!
Run Docker
Time to collect the reproducible fruits of your labor! You can now run your container:
docker run -p 8888:8888 video_augmentation
You will be able to check the progress of your execution and interact with your notebook here: http://localhost:8888

Note that the notebook may be password or token protected. When you see the message “Token authentication is enabled” when accessing `http://localhost:8888`, you’ll need to obtain the token that was generated when the Jupyter server started, either from the Docker container logs in the terminal or Docker Desktop (Containers>Three dots>Show Container Actions>View Details).
Sharing a Docker image typically involves publishing the image to a container registry or sharing it as a package, depending on your use case. Docker Hub is a popular public container registry where you can publish and share Docker images.In addition to Docker Hub, there are other container registries like Amazon ECR, Google Container Registry (GCR), and Azure Container Registry (ACR). You can use similar `docker push` commands to publish your image to these registries.
You can create a Docker Hub account, log in, and then use the `docker push` command to upload your image to Docker Hub. Here are the steps I used:
- Tag your Docker image with a name that includes your Docker Hub username and the desired repository name. Replace in the code below ‘your-username’ with, your Docker Hub username, and ‘tag’ with something to identify this push, e.g. ‘initial’:
docker build t- your-username/video_augmentation:tag
- Log in to Docker Hub (you will be prompted for your password):
docker login -u your-username
- Push the image to Docker Hub:
docker push your-username/video_augmentation:initial
If everything went as it should, you should now see the ‘initial’ in your Docker hub.
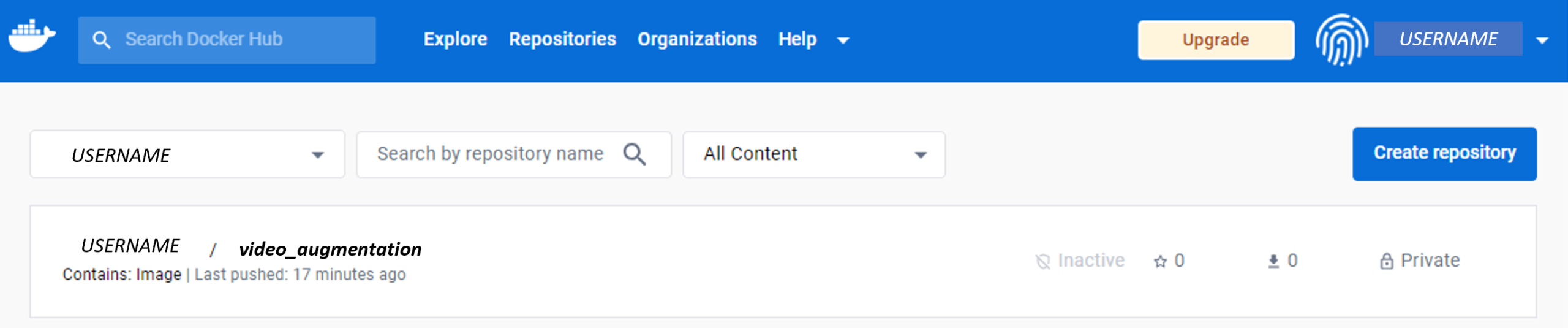
Hopefully now you can achieve Jupyter reproducibility with Docker. I hope this was useful. I know it will be useful to future me! Feedback is welcome.
About Rosan International
ROSAN is a technology company specialized in the development of Data Science and Artificial Intelligence solutions with the aim of solving the most challenging global projects. Contact us to discover how we can help you gain valuable insights from your data and optimize your processes.